"Airwalk Reply brought energy and resolutions to a very large piece of work that had been drifting for 12 months"
"Excellent leadership style from Airwalk Reply who genuinely brought industry expertise to the table, would sit down and go above and beyond on certain topics"
"The project with Airwalk Reply has driven the biggest culture change I've seen in the bank in my 28 years... we are now reporting at Board level"
"The work you're doing is adding tons of value, its brilliant, really"
“Airwalk provided excellent solutions on how to help us move forward, and we really enjoyed working with you”
"It has been great having the team from Airwalk Reply do this work! We would never have had the headspace to do this, and we wouldn't have considered all of the avenues they have taken us down"
"Airwalk Reply is able to breakdown highly technical subjects into something consumable"
"My dealings with Airwalk Reply have always been extremely positive; the can-do attitude is refreshing"
“We have never seen our head of architecture so happy”
"Thank you for your efforts; it's an excellent piece of work that has made improvements across the organisation"
"I just wanted to say a massive thank you for the demo, we don't do it often enough. It's great to see it coming together, and it worked!"
"Airwalk Reply bring energy and is adding value above what was originally expected"
"Over the past year, the collaboration between Airwalk Reply, LSEG, and Microsoft has demonstrated the power of partnership and shared goals"
"Airwalk Reply brings new stuff to the table, they understand the business objectives, so there is always alignment"
“The relationship with Airwalk Reply is really good, open and transparent; unlike other consultancies, we didn’t feel that there was a hard sell”
"Airwalk Reply is not like other consultancies, they are brilliant and we know they will bring huge value"
"Appreciated your candidacy and openness in discussions to understand our organisation"
"Airwalk Reply is full of superstars"
"I actually had my reservations at the start about how much benefit we would get, but I must say that I am super impressed!"
"The Airwalk team consistently delivered and provided valuable input into shaping and implementing the ways of working and the delivery"
"I have had nothing but positive comments on the material delivered by Airwalk Reply. Thanks for your fantastic support"
"The technical input helped change and shape the technical patterns and tools that have led to success"
"I would recommend Airwalk and already have them working on other engagements"
"Airwalk Reply provides a more flexible, bespoke service, working collaboratively with the teams. There are regular catch-ups in place to check that the team is all on track and deliverables are progressing in line with expectations"
"The specific reference architecture is likely to be adopted at a group level, and the template is definitely being used across other platforms/domains"
"The regulator has praised us for our transparent, proactive approach, which has already resulted in a large reduction in non-current software on the estate"
"Airwalk Reply do not shy away from challenges, and always with a positive attitude"
"Airwalk Reply is seen as a partner, not a vendor"
"They have experience in large organisations with similar challenges, so they are able to think about the bigger picture, and this was evidenced in the well-thought-through assessment and framework"
"Impressive, the real deal"
"Airwalk and Microsoft's agility and customer focus, combined with an effective feedback loop, have not only met objectives but set a benchmark for industry collaboration and success"
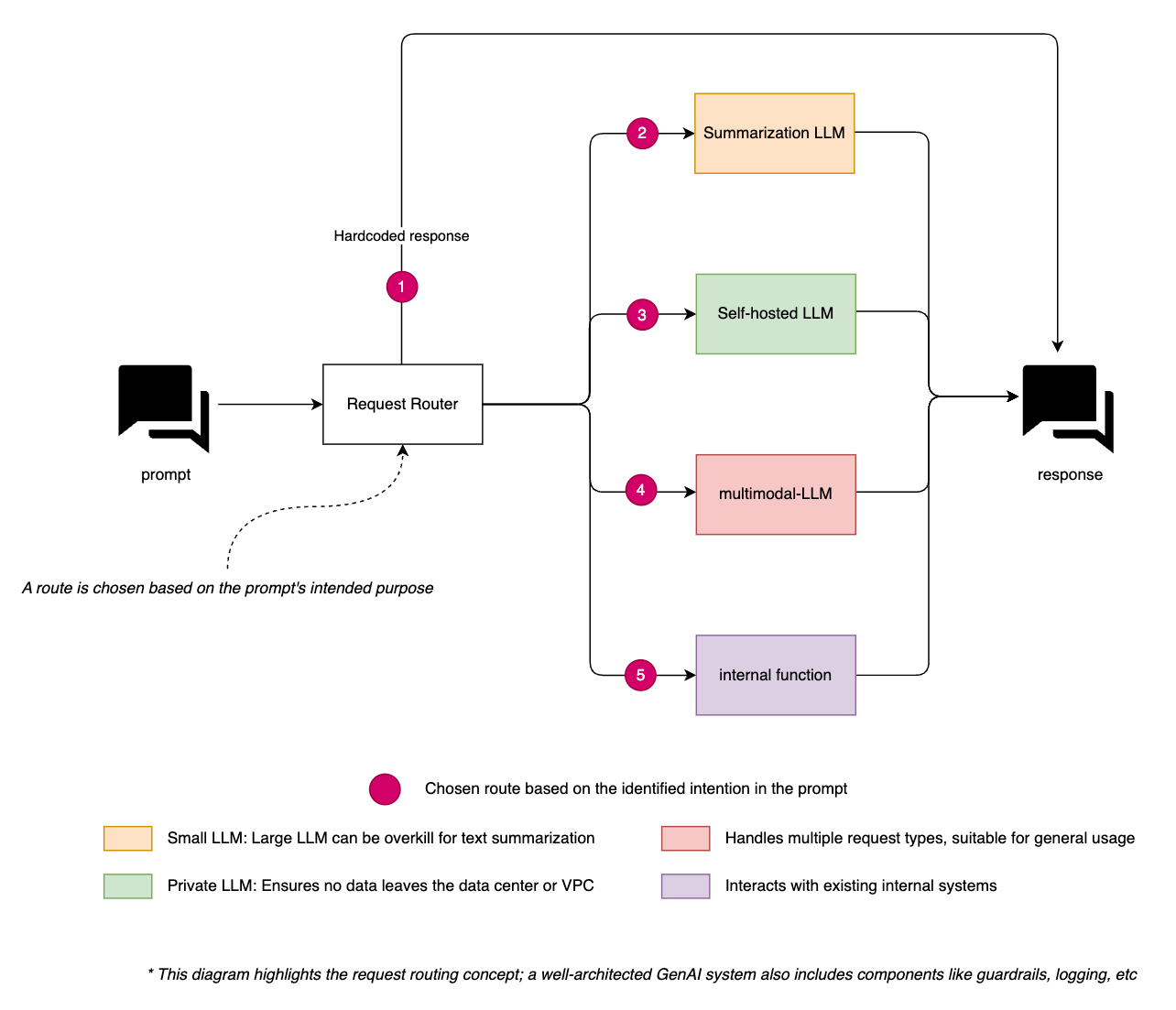

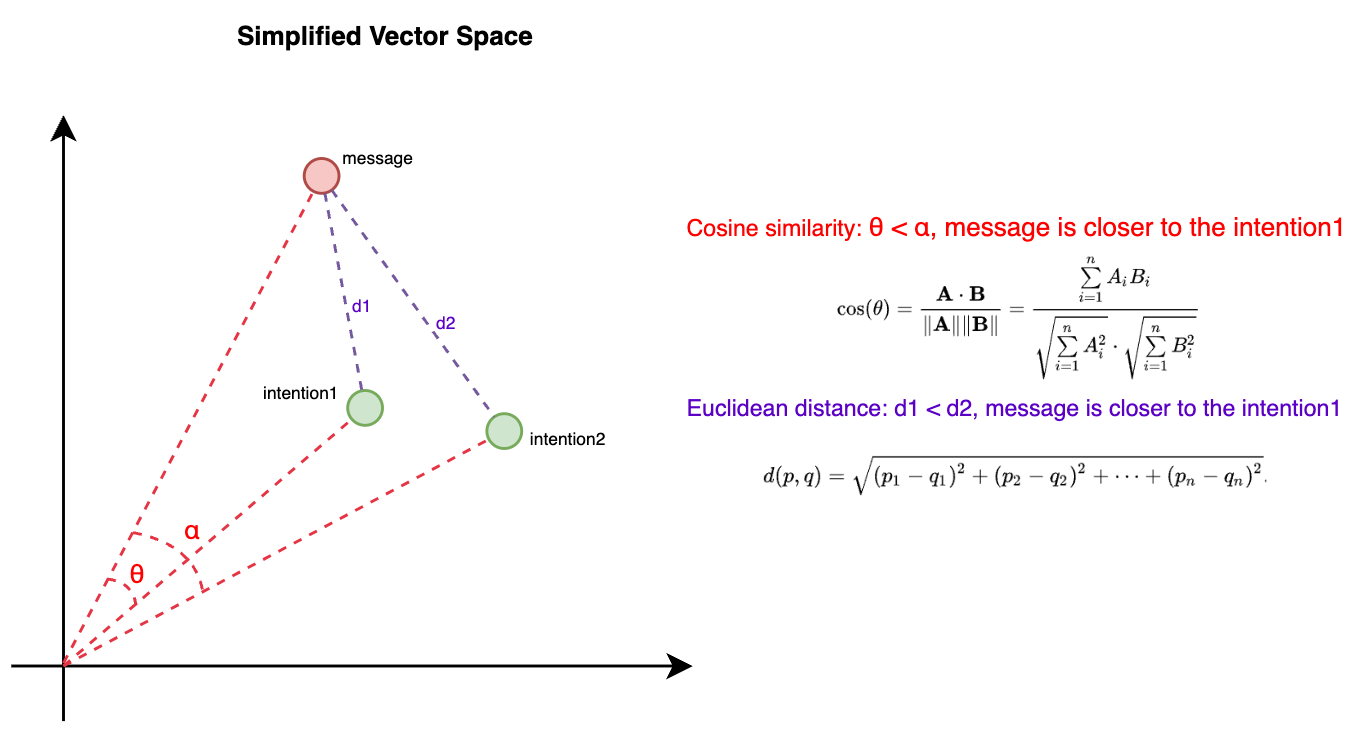 Techniques like cosine similarity or Euclidean distance are commonly used for these comparisons. Cosine similarity measures the cosine of the angle between two vectors, providing a metric for how similar the vectors (and thus the messages) are. Euclidean distance, on the other hand, calculates the straight-line distance between two points in the vector space. These methods ensure that the most appropriate response or action is taken based on the identified intent, providing a precise and efficient way to handle diverse requests by leveraging the geometric properties of vector spaces.
Techniques like cosine similarity or Euclidean distance are commonly used for these comparisons. Cosine similarity measures the cosine of the angle between two vectors, providing a metric for how similar the vectors (and thus the messages) are. Euclidean distance, on the other hand, calculates the straight-line distance between two points in the vector space. These methods ensure that the most appropriate response or action is taken based on the identified intent, providing a precise and efficient way to handle diverse requests by leveraging the geometric properties of vector spaces.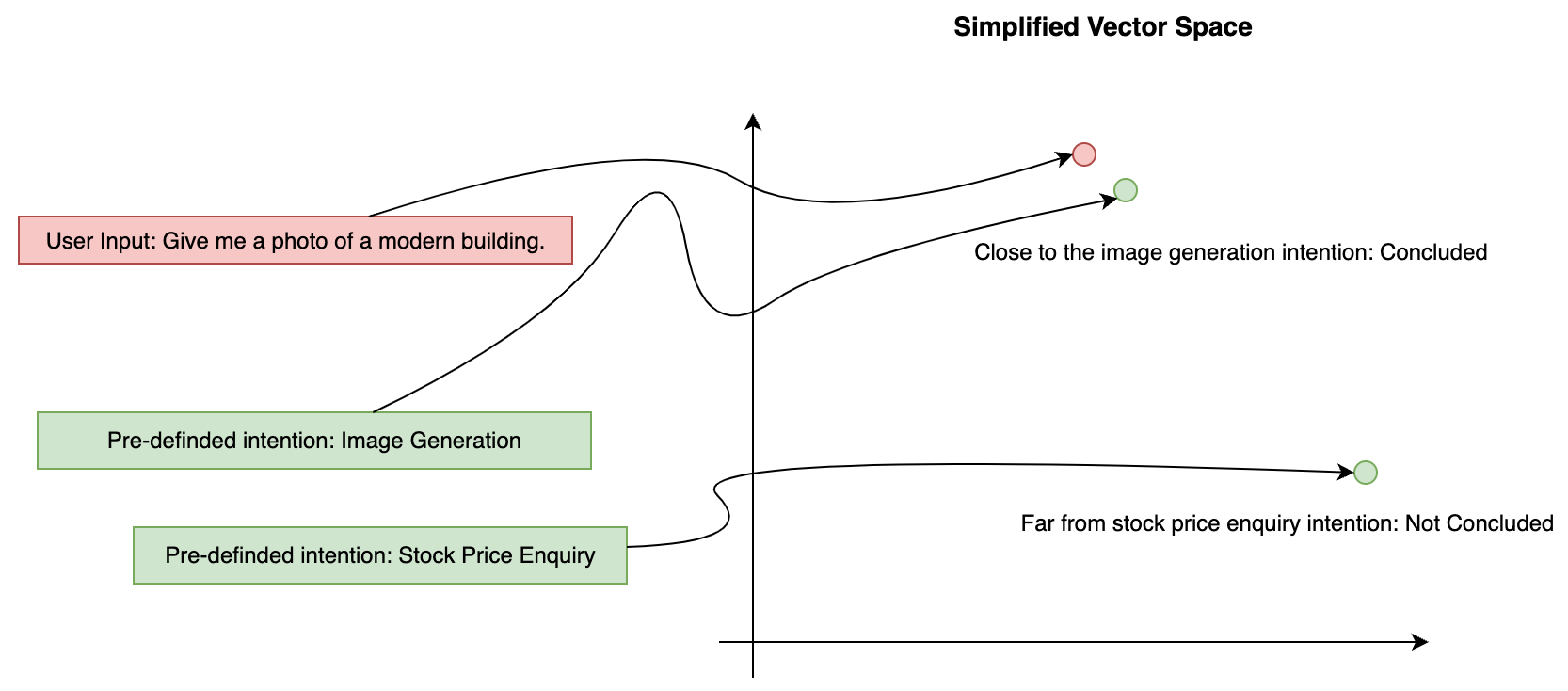
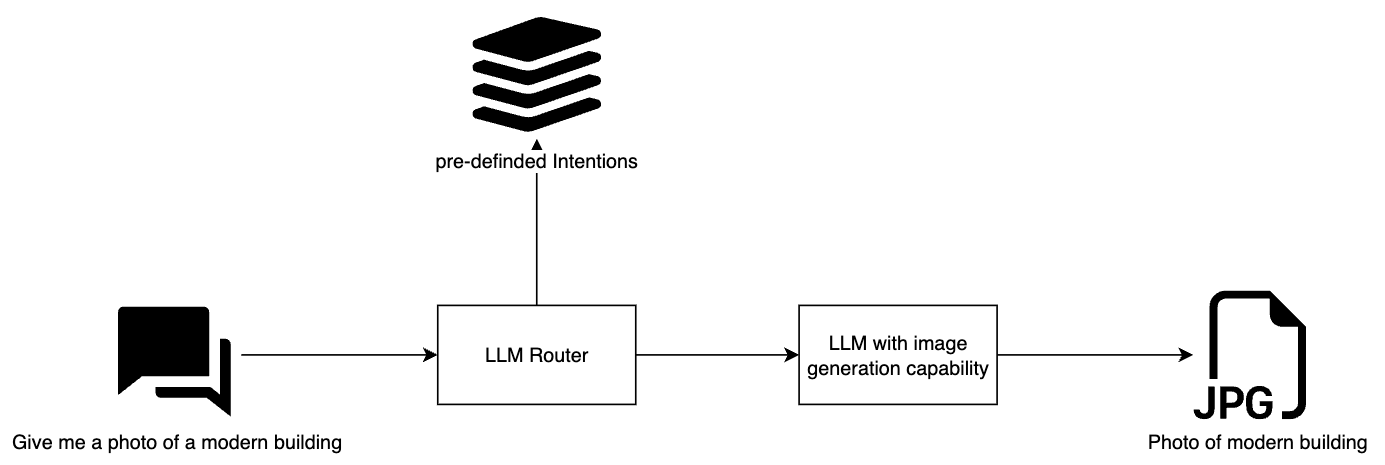
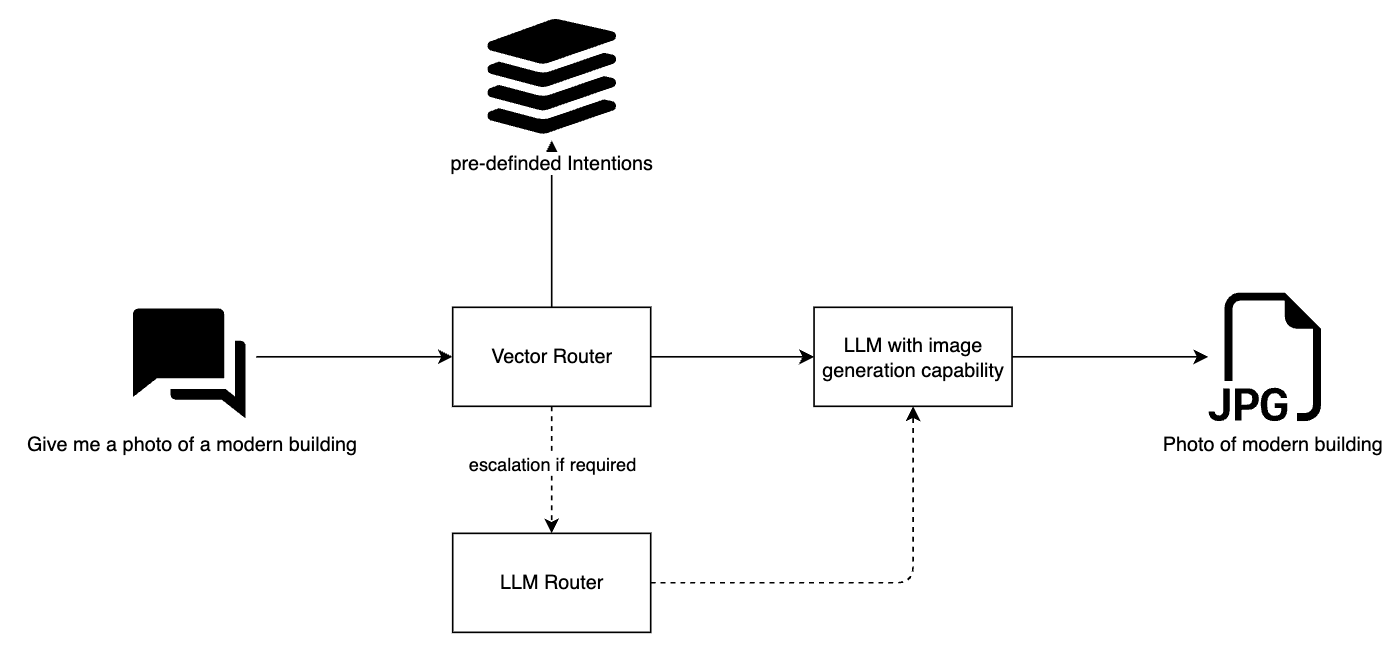
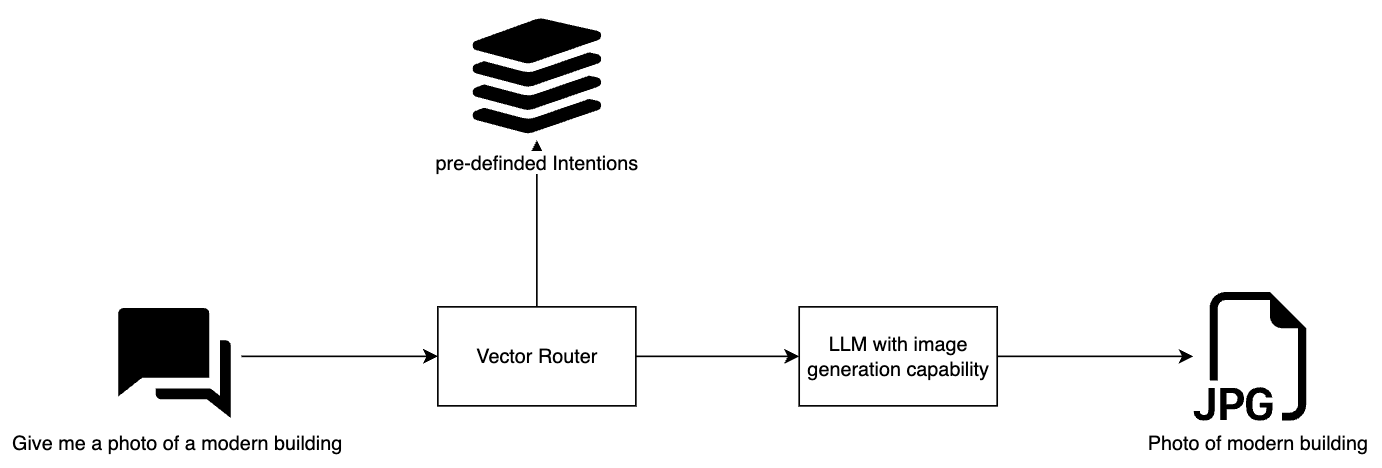 Hybrid Routing combines the strengths of both approaches. It uses Vector-based routing as the base layer, supplemented by an LLM escalation mechanism. This hybrid model offers a great balance between cost, performance, and accuracy, making it the preferred choice for systems that require both quick responses and high reliability.
Hybrid Routing combines the strengths of both approaches. It uses Vector-based routing as the base layer, supplemented by an LLM escalation mechanism. This hybrid model offers a great balance between cost, performance, and accuracy, making it the preferred choice for systems that require both quick responses and high reliability.