Forward proxy setup is mandatory for a modern network topology, especially for those running in a public cloud. It is able to serve as a gatekeeper between boundaries of different network zones for security purposes. For example, using outbound forward proxies to the public Internet can be used to filter all outgoing destinations and it can make sure only whitelisted domains are allowed to egress. Likewise, a forward proxy between cloud and on-premise environments helps to gain control of traffic to appropriate on-premise endpoints.
The weakest link
However, it implies the forward proxy is the weakest link of a complex network. Once a forward proxy goes down or malfunctions for whatever reason, all traffic to the Internet or on-premise networks will be impacted.
Traditional health check
Some cloud providers do provide some health check facilities. In AWS, an Elastic Load Balancer (ELB), particularly Network Load Balancer (NLB), usually sits in front of a set of forward proxy instances and the lifecycle of them is controlled by an autoscaling group (ASG) to serve the resiliency. Periodically, the NLB could do a health check, by using predefined TCP and HTTP requests, to each proxy instances and if any proxy instance does not respond with successful connection for TCP or predefined status code (eg. 200) for HTTP, the NLB will determine that the instance is unhealthy. If the ASG is configured to use the NLB health check, it will replace the unhealthy instance with a new and healthy instance.
Problem
It sounds good. But the above health check mechanism does not truly reflect how the forward proxy should behave. When a client sends an HTTP request to an endpoint, by setting the use of a forward proxy, the client should contact the proxy and ask it to forward the request to the destination and return the response back to the client. The NLB health check is simply making a direct TCP connection or HTTP request to the proxy itself. Murphy’s Law implies that even the NLB, as in the above case, receives a valid response, but the forward proxy could still be malfunctioning for some reason and the network could be found to be acting up, although we believed the NLB and ASG should have correctly handled the failure of the proxy service.
Challenges
Then we need to have a more accurate way of detecting a failure of a forward proxy and a self-healing mechanism. It is not without challenges. For example, in AWS, we are not able to configure the NLB to use a forward proxy to send a health check request, which is to mimic the proper behaviour of a forward proxy. To do that, we could setup a specific service to do the health check. The service could send an HTTP request to some endpoints with the use of the forward proxy. If the health check service receives a valid response, this means that the proxy behaved properly and forwarded the request. But the first challenge is that we would need to handle the self-healing mechanism on our own, i.e. detach and kill the failing instance, start up and attach a new instance to the load balancer. The clumsy mechanism should be ideally handled by the NLB and ASG. The second challenge is to determine what endpoint should be used in the health check. If the failing health check is due to the remote endpoint failing itself, the self-healing mechanism will destroy all functioning instances and turns out to be a disaster.
A simple solution
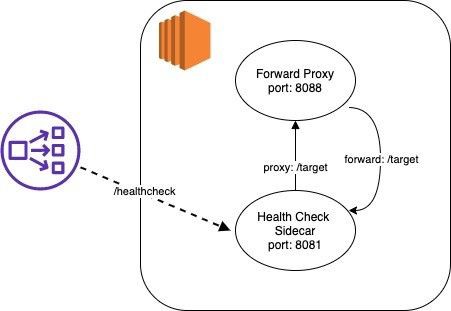
A viable solution should tackle the above two challenges. The ideal thing is we can still make use of the NLB health check and self-healing mechanism. If the NLB sending a health check request to the forward proxy is not robust enough, why not set up a sidecar process in the same host as the forward proxy to receive the health check request from the NLB? The sidecar process should be able to send another health check to some endpoint via the forward proxy. If the process receive a valid response then it means the forward proxy is indeed functioning. Then the process returns a successful status code to the NLB and it signals to the NLB that the forward proxy is functioning. The port the process binds needs to be different from the port where the proxy listens as they are sitting in the same host. Fortunately, AWS provides this feature in the NLB target group setting.
Next comes to the second challenge of how to define the appropriate endpoint for the proxied request. A local endpoint (i.e. http://localhost), which should be more robust than any other external one, is an ideal candidate. It can be set up in the same sidecar process described in the previous paragraph.
We now have a new sidecar process with two endpoints, one for receiving health check requests from the NLB and another serving as the “remote” endpoint for the requests originated by itself and sent via the forward proxy. This is illustrated in the below diagram.
The logic is also simple. The below code snippet is written in Python using a web framework Flask. It shows how the implementation looks like. It assumes that the proxy service and sidecar health check process are bind on port 8088 and 8081 respectively.
The health check process runs as a daemon or a system service. For example, on Linux OS, the daemon could be managed by systemd.
If the proxy service is down or malfunctions for any reason, the sidecar health check process will return a non-200 status code to the NLB. The ASG will kill the whole instance and launch a new instance with a healthy proxy service and sidecar health check process.
You may ask, what if the sidecar process is down or malfunctions? The NLB is then not able to receive a valid response and simply determines that the instance is not healthy and it should be replaced with a new and healthy one.